이번 주 역대급으로 미루고 미루고 미루고 ... x8687978743번 미루고
일요일에 몰아서 끝내다보니 너무 많은 내용들이 뒤죽박죽이라 어렵습니다..
ㅅr 실 저번 주에 우수 혼공단 포기하고 (똑똑한 사람들이 공부를 오만배 열심히 하더라고요)
혼자 열심히 했더니 삐진(?) 제 마음을 알아주시곤 감사하게도 선정되었더라고요 🥹
남은 기간도 열심히 하겠습니다.. (이번 주는 빼고..)
갈수록 힘들어져요🫥
Ch 06 메모리와 캐시 메모리
06-1 RAM의 특징과 종류
+) 주기억장치(메인 메모리)의 종류에는 RAM과 ROM 두 가지가 있고, '메모리'란 용어는 그중 RAM을 지칭하는 경우가 많다.
RAM의 특징

RAM은 전원이 꺼지면 내용이 사라지기 때문에 : 휘발성 저장 장치
전원이 꺼져도 저장된 내용이 유지되기 때문에 : 비휘발성 저장 장치 (CPU가 직접 접근하진 못함)
CPU가 실행하고 싶은 프로그램이 보조기억장치에 있다면 이를 RAM으로 복사하여 저장한 뒤 실행한다.
휘발성 저장장치 : 전원을 끄면 저장된 내용이 사라지는 저장장치
비휘발성 저장장치 : 전원이 꺼져도 저장된 내용이 유지되는 저장장치
RAM의 용량과 성능
- RAM의 용량이 작은 경우
: 보조기억장치에서 실행할 프로그램을 가져오는 일이 잦아 실행 기간이 길어짐.
- RMA의 용량이 클 경우
: RAM의 용량이 크면 많은 프로그램을 동시에 빠르게 실행하는 데 유리하다.
→ RAM의 용량이 크면 여러 프로그램을 빠르게 실행할 수 있지만, 필요 이상 커진다면 실행 속도는 그에 비례하게 빨라지지 않는다. RAM과 보조기억장치 사이의 오가는 시간은 별 차이 없기 때문.
RAM의 종류
DRAM, SRAM, SDRAM, DDR SDRAM
DRAM ( Dynamic RAM ) / Dynamic = ‘동적의’
- 저장된 데이터가 동적으로 사라지는 RAM
- 데이터 소멸을 막기 위해 주기적으로 재활성화해야 함. refresh
- 일반적으로 메모리로 사용되는 RAM
↪상대적으로 소비전력이 낮고 저렴하고 집적도가 높아 대용량으로 설계하기 용이하기 때문이다.
SRAM ( Static RAM ) / Static = ‘정적의’
- 저장된 데이터가 정적인 (사라지지 않는 ) RAM
- DRAM 보다 일반적으로 더 빠름
- 전원이 공급되지 않으면 꺼짐 (휘발성)
- 일반적으로 캐시 메모리에서 사용되는 RAM ** 캐시 메모리 중요
↪ 상대적을 소비전력이 높고 가격이 높고 집적도가 낮아 “대용량으로 설계할 필요는 없으나 빨라야 하는 장치”에 사용
DRAM vs SRAM ** 두 차이를 아는 것이 중요

- DRAM은 많은 용량을 담는 메모리로서 사용된다.
- SRAM은 대용량은 굳이이지만 빨라야 하는 캐시 메모리로 사용된다.
SDRAM (Synchronous(동기화) DRAM )
- 특별한 (발전된 형태의) DRAM
- 클럭 신호와 동기화된 DRAM (클럭 타이밍에 맞춰 CPU와 정보를 주고받을 수 있음을 의미 )
- 클럭에 맞춰 동작하며 클럭마다 CPU와 정보를 주고받을 수 있는 DRAM이다.
DDR SDRAM (Double Data Rate SDRAM )
- 특별한 (발전된 형태의) SDRAM
- 최근 가장 대중적으로 사용하는 RAM
- 대역폭을 넓혀 속도를 빠르게 만든 SDRAM
- 대역폭은 데이터를 주고받는 길의 너비
+) DDR SDRAM vs SDRAM (SDR single data rate SDRAM)

DDR 2 SDRAM vs DDR SDRAM ( 2배/ SDR SDRAM보다 너비가 네 배 )
DDR3 SDRAM vs DDR2 SDRAM ( 대역폭 2배 / SDR SDRAM보다 대역폭 여덟 배 )
최근에 흔히 사용하는 메모리 DDR4 SDRAM , SDR SDRAM보다 열여섯 배 넓은 대역폭 가짐.
06 - 2 메모리의 주소 공간
물리 주소와 논리 주소
물리 주소 : 메모리 하드웨어가 사용하는 주소
논리 주소 : CPU와 실행 중인 프로그램이 사용하는 주소
CPU와 메모리에 저장되어 실행 중인 프로그램은 메모리 몇 번지에 무엇이 저장되어 있는지 다 알지 못한다.
( 불가능에 가까움 )
메모리에 저장된 값들은 시시각각 변하기 때문이다.
- 새롭게 실행되는 프로그램은 새롭게 메모리에 적재
- 실행이 끝난 프로그램은 메모리에서 삭제
- 같은 프로그램을 실행하더라도 실행할 때마다 적재되는 주소는 달라짐

물리 주소
- 메모리 입장에서 바라본 주소
- 말 그대로 정보가 실제로 저장된 하드웨어상의 주소
논리 주소
- CPU와 실행 중인 프로그램 입장에서 바라본 주소
- 실행 중인 프로그램 각각에게 부여된 0번지부터 시작하는 주소

MMU (메모리 관리 장치)라는 하드웨어에 의해 변환 (변환을 이루어주는 장치 필수!)

→ MMU는 논리 주소와 베이스 레지스터(프로그램의 기준(시작) 주소) 값을 더하여
논리 주소를 물리 주소로 변환

→베이스 레지스터 : 프로그램의 가장 작은 물리 주소 (프로그램의 첫 물리 주소)를 저장하는 셈
→ 논리 주소 : 프로그램의 시작점으로부터 떨어진 거리인 셈
메모리 보호 (기법)
이런 명령어는 실행되어도 안전할까?

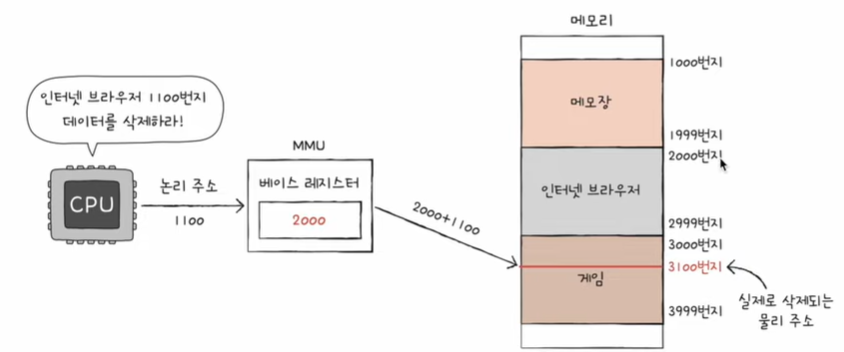
이렇게 다른 프로그램의 영역을 침범할 수 있는 명령어는 위험.
한계 레지스터
→ 논리 주소 범위를 벗어나는 명령어 실행을 방지하고 실행 중인 프로그램이 다른 프로그램에 영향을 받지 않도록 보호하는 것을 담당 ( 프로그램의 영역을 침범할 수 있는 명령어의 실행을 막음)
→ 베이스 레지스터가 실행 중인 프로그램의 가장 작은 물리 주소를 저장한다면, 한계 레지스터는 논리 주소의 최대 크기를 저장
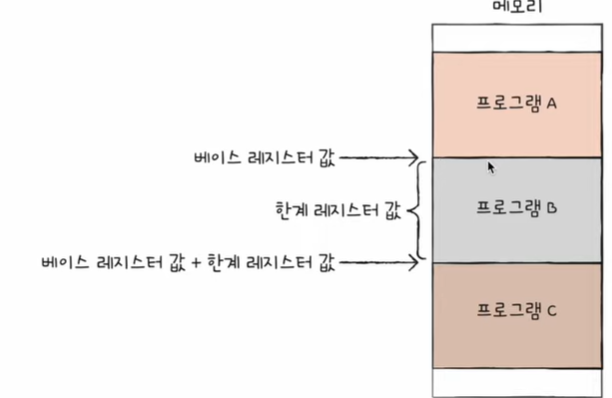
→ 베이스 레지스터 값 <= 프로그램의 물리 주소 범위 < 베이스 레지스터 + 한계 레지스터 값
cpu가 접근하려는 논리 주소는 한계 레지스터가 저장한 값보다 커서는 안 됨.
실행 중인 프로그램의 독립적인 실행 공간을 확보 & 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호
06 - 3 캐시 메모리

→ CPU가 메모리에 접근하는 시간은 CPU 연산 속도보다 느리다!!
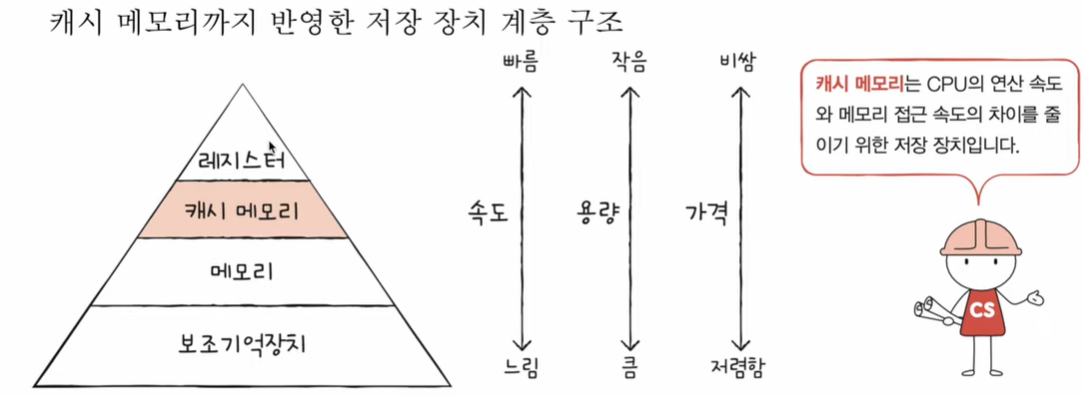
저장 장치 계층 구조
CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
속도가 빠른 저장 장치는 용량이 적고, 가격이 비싸다.
레지스터 vs 메모리 RAM vs USB 메모리
낮은 가격대의 대용량 저장장치를 원한다면 느린 속도는 감수해야 하고,
빠른 속도의 저장 장치를 원한다면 작은 용량과 비싼 가격은 감수해야 한다.
저장 장치들은 ‘CPU에 얼마나 가까운가’를 기준으로 계층적으로 나타낼 수 있음.

캐시 메모리
: CPU와 메모리 사이에 위치한 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치 (용어 의미)
CPU의 연산 속도와 메모리 접근 속도의 차이를 조금이나마 줄이기 위해 탄생

메모리에 접근 ≒ 물건을 많이 사러 가는 것
메모리 ≒ 물건은 많지만 집과는 멀리 떨어져 있어 왕복이 오래 걸리는 대형 마트
캐시 메모리 ≒ 물건이 많지는 않아도 집과 가까이 있는 편의점

계층적 캐시 메모리 (L1 - L2 - L3 캐시)

+) 일반적으로 L1 캐시와 L2 캐시는 코어 내부에, L3 캐시는 코어 외부에 위치해 있다.
멀티코어 프로세서 캐시 메모리

+) 분리형 캐시
L1 캐시 조금이라도 접근 속도를 빠르게 만들기 위해 명령어 만을 저장하는 L1 캐시인 L1|캐시와 데이터 만을 저장하는 L1캐시인 L1D캐시로 분리하는 경우도 있다. 이를 분리형 캐시라고 함.

계층적 캐시 메모리까지 반영한 저장 장치 계층 구조 ↴
참조 지역성 원리
Q) 캐시 메모리는 메모리보다 용량이 작다. 당연하게도 메모리의 모든 용량을 저장할 수 없다.
뭘 저장해야 할까??
→CPU가 자주 사용할 법한 내용을 예측하여 저장해야 한다.
예측이 들어맞을 경우 (CPU가 캐시 메모리에 저장된 값을 활용할 경우) == 캐시 히트
예측이 틀렸을 경우 (CPU가 메모리에 접근해야 하는 경우 ) == 캐시 미스 (성능 하락!)
캐시 적중률 : 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
→ 캐시 적중률이 높으면 CPU의 메모리 접근 횟수를 줄일 수 있다.
→ 캐시 적중률을 높여야 한다 == CPU가 사용할 법한 데이터를 잘 예측해야 한다!
CPU가 사용할 법한 데이터를 예측하는 방법, 참조 지역성의 원리
참조 지역성의 원리?
CPU가 메모리에 접근할 때의 주된 경향을 바탕으로 만들어진 원리
2가지의 경향 ↴
CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다. (시간 지역성)
CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다. (공간 지역성)
Ch 07 보조기억장치
07 - 1 다양한 보조기억장치
하드 디스크 – 저장 단위
자기적인 방식으로 데이터 저장
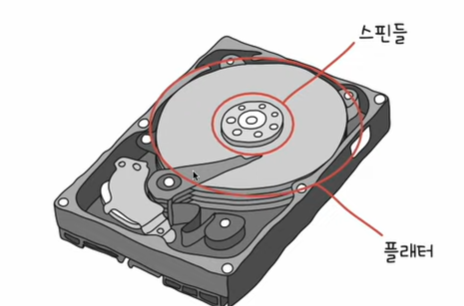
일반적으로 플래터 양면 모두 사용
RPM (Revolution Per Minute) : 분당 회전수
플래터 : 하드 디스크에서 실질적으로 데이터가 저장되는 곳.
스핀들: 플래터를 회전시키는 구성 요소

헤드 : 플래터를 대상으로 데이터를 읽고 쓰는 구성 요소
디스크 암: 헤드는 원하는 위치로 헤드를 이동시키는
디스크 암에 부착되어 있다.
일반적으로 모든 헤드가 디스크 암에 부착되어 함께 이동.

연속된 정보는 한 실린더에 기록.

기본적으로 트랙 track과 섹터 sector
단위로 데이터 저장.
섹터의 크기 : 512바이트 ~4096바이트
하나 이상의 섹터를 묶어 블록 (block)이라고 표현하고 한다.

여러 겹의 플래터 상에서 같은 트랙이
위치 한 곳을 모아 연결한 논리적 단위.
플래터는 트랙과 섹터로 나뉘고, 같은 트랙이 모여
실린더(cylinder)를 이룬다.
하드 디스크 – 데이터 접근 과정
하드 디스크가 저장된 데이터에 접근하는 시간
탐색 시간 seek time / 회전 지연 rotational latency / 전송 시간 transfer time
탐색 시간 (seek time)
: 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간

회전 지연 (rotational latency)
: 헤드가 있는 곳으로 플래터를 회전시키는 시간을 의미함.

전송 시간 (transfer time)
: 하드 디스크와 컴퓨터 간에 데이터를 전송하는 시간을 의미한다.

+) Jeff Dean – Numbers Every Programmer Should Know

ns 나노초는 10-9초
패킷 (packet)이란 네트워크의 기본적인 전송 단위.
플래시 메모리 – 저장 단위
: 전기적으로 데이터를 읽고 쓰는 반도체 기반 저장 장치
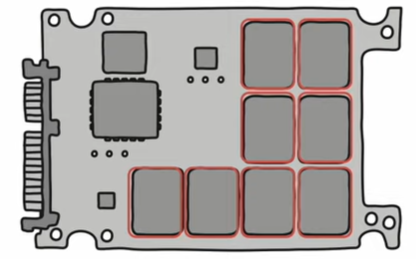
범용성이 넓기에 보조기억장치에 ‘만’ 속한다고 보기는 어려움.
+) 플래시 메모리 종류 : NAND / NOR 플래시 메모리 → 오늘날 대용량 저장 장치로 많이 사용되는 건 NAND 플래시 메모리. 여기서 보조기억장치로서의 플래시 메모리 또한 NAND.
셀 (cell)
플래시 메모리에서 데이터를 저장하는 가장 작은 단위
이 셀이 모이고 모여 MB, GB, TB 저장 장치가 된다.
한 셀에
- 1 비트를 저장할 수 있는 플래시 메모리: SLC
- 2 비트를 저장할 수 있는 플래시 메모리: MLC
- 3 비트를 저장할 수 있는 플래시 메모리: TLC
- 4 비트를 저장할 수 있는 플래시 메모리: QLC
사람 한 명 == 1비트 / 셀 == 집
→ SLC == 한 집에 한 명 / MLC == 한 집에 두 명 / TLC == 한 집에 세 명
SLC

- 한 셀로 두 개의 정보 표현
- 비트의 빠른 입출력
- 긴 수명
- 용량 대비 고가격
+) 플래시 메모리(USB, SSD, SD카드) 하드 디스크에는 수명이 있다.
MLC
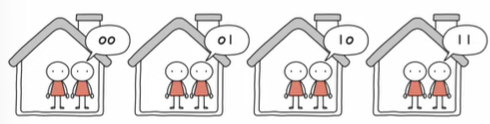
- 한 셀로 네 개의 정보 표현 ( 대용량화 유리)
- SLC보다 느린 입출력
- SLC보다 짧은 수명
- SLC보다 저럼
- 시중에서 많이 사용 (MLC, TLC, QLC)
TLC

- 한 셀로 여덟 개의 정보 표현 (대용량화 유리)
- MLC보다 느린 입출력
- MLC보다 짧은 수명
- MLC보다 저렴
- 시중에서 많이 사용
∴ 이를 통해 알 수 있는 점 : 같은 플래시 메모리라도 수명, 가격, 성능이 다르다.


셀들이 모여서 페이지 (page)
페이지들이 모여 블록 (block)
블록이 모여 플래인 (plane)
플레인이 모여 다이 (die)
(플래시 메모리의) 읽기 쓰기 단위와 삭제의 단위가 다르다.
읽기와 쓰기는 페이지 단위로 이루어짐.
삭제는 (페이지보다 큰) 블록 단위로 이루어짐.
(읽기와 쓰기가 페이지 단위로 이루어지는데 이는 상태를 가질 수 있다. )
페이지의 상태
Free 상태
: 어떠한 데이터도 저장하고 있지 않아 새로운 데이터를 저장할 수 있는 상태
Valid 상태
: 이미 유효한 데이터를 저장하고 있는 상태
Invalid 상태
: 유효하지 않은 데이터 (쓰레기 값)를 저장하고 있는 상태
+) 플래시 메모리는 하드 디스크와 달리 덮어쓰기가 불가능함.
+) 플래시 메모리 동작 예시
블록 X에 새로운 데이터 C를 저장하는 경우. 읽기 쓰기 단위는 페이지이므로 아래와 같이 저장.

새롭게 저장된 C와 기존에 저장되어 있는 B는 그대로 둔 채, 기존의 A만을 A’로 수정.
가비지 컬렉션

- 유효한 페이지들만을 새로운 블록으로 복사
- 기존의 블록을 삭제
07-2 RAID의 정의와 종류
RAID의 정의 (Redundant Array of Independent Disks)
- 하드 디스크와 SSD로 사용하는 기술
- 데이터의 안전성 혹은 높은 성능을 위해 여러 물리적 보조기억장치를 마치
- 하나의 논리적 보조기억장치처럼 사용하는 기술.

1TB 하드 디스크 네 개로 RAID를 구성하면
4TB 하드 디스크 한 개의 성능과 안전성을
능가할 수 있다.
<RAID의 종류>
RAID 레벨
- RAID를 구성하는 기술
- RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6
- 그로부터 파생된 RAID 10, RAID 50 •••
RAID 0 : 데이터를 단순히 나누어 저장하는 구성 방식

각 하드 디스크는 번갈아 가며 데이터를 저장한다.
저장되는 데이터가 하드 디스크 개수만큼 나뉘어 저장.
스트라입 (stripe) : 마치 줄무늬처럼 분산되어 저장된 데이터
스트라이핑(striping): 분산하여 저장하는 것
raid 0 장점: 입출력 속도의 향상

raid 0 단점 : 저장된 정보가 안전하지 않음

하드 디스크가 고장이 나면
저장할 수가 없음.
RAID 1
미러링 (mirroring) : 복사본을 만드는 방식
데이터를 쓸 때 원본과 복사본 두 군데에 씀 (느린 쓰기 속도)

장점: 백업과 복구가 정말 쉽다. (위와 달리 다른 게 고장이 나도 작동 가능함.)
단점: 하드 디스크 개수가 한정되었을 때 사용 가능한 용량이 적어짐
복사본이 만들어지는 용량만큼 사용 불가 → 많은 양의 하드 디스크가 필요 → 비용 증가
RAID 4
(RAID 1처럼 완전한 복사본을 만드는 대신) 패리티 비트 ( == 오류를 검출하고 복구하기 위한 정보)를 저장
패리티를 저장한 장치를 이용해 다른 장치들의 오류를 검출하고, 오류가 있다면 복구
+) 패리티 비트는 오류 검출만 가능할 뿐 오류 복구는 불가능.

RAID 4 단점 : 패리티 디스크의 병목(현상이 생길 수 있다.)
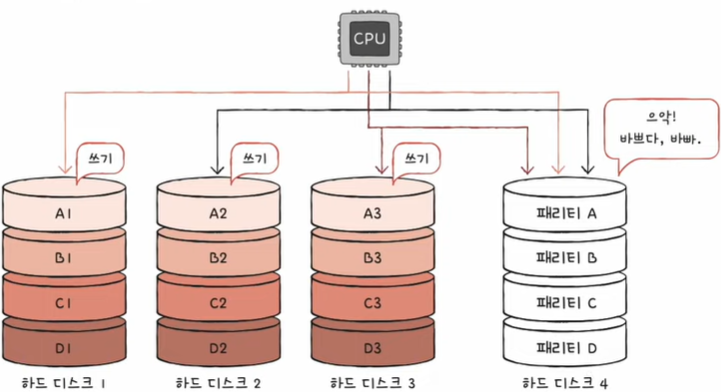
RAID 5
: 패리티 정보를 분산하여 저장하는 방식

RAID 6
두 종류의 패리티 (오류를 검출하고 복구할 수 있는 수단)
RAID 5보다 안전, 쓰기는 RAID 5보다 느림

∴
- 각 RAID 레벨마다 장단점이 있음
- 어떤 상황에서 무엇을 최우선으로 원하는지에 따라 최적의 RAID 레벨은 달라질 수 있음
- 각 RAID 레벨의 대략적인 구성과 특징을 아는 것이 중요
Ch 08 입출력장치
08 - 1 장치 컨트롤러와 장치 드라이버
+) 이 장에서 말하는 입출력장치는 보조기억장치도 포함됨.
장치 컨트롤러
Q) 입출력장치는 앞서 학습한 CPU, 메모리보다 다루기가 더 까다롭다. WHY??
1. 입출력장치에는 종류가 너무나도 많음.
장치가 다양하면 장치마다 속도, 데이터 전송 형식 등도 다양하다.
→ 다양한 입출력장치와 정보를 주고받는 방식을 규격화하기 어렵다.
2. 일반적으로 CPU와 메모리의 데이터 전송률은 높지만 입출력장치의 데이터 전송률은 낮다.
+) 전송률: 데이터를 얼마나 빨리 교환할 수 있는지를 나타내는 자료

→ 이런 이유로 입출력장치는 장치 컨트롤러를 통해 컴퓨터와 연결된다.
장치 컨트롤러의 역할
- CPU와 입출력장치 간의 통신중개 (일종의 번역가)
- 오류 검출
- 데이터 버퍼링 ( 버퍼링 : 전송률이 높은 장치와 낮은 장치 사이에 주고받는 데이터를 버퍼라는 임시 저장 공간에 저장하여 전송률을 비슷하게 맞추는 방법)

장치 컨트롤러의 구조

+) 상태 레지스터와 제어 레지스터는 하나의 레지스터 ( 상태/제어 레지스터)로 사용되기도 함.
데이터 레지스터
- CPU와 입출력장치 사이에 주고받을 데이터가 담기는 레지스터 ( 버퍼 역할을 함)
- RAM을 사용하기도 함 (최근 주고받는 데이터가 많은 입출력장치에서는)
상태 레지스터
- 상태 정보 저장 ( 입출력 장치가 입출력 작업을 할 준비가 되었는지, 입출력 작업이 완료되었는지, 입출력장치에 오류는 없는지 등)
제어 레지스터
- 입출력장치가 수행할 내용에 대한 제어 정보
장치 드라이버
: 장치 컨트롤러의 동작을 감시하고 제어하는 프로그램
( 장치 컨트롤러가 입출력장치를 연결하기 위한 하드웨어적 통로라면,
장치 드라이버는 입출력장치를 연결하기 위한 소프트웨어적인 통로)

컴퓨터(운영체제)가 연결된 장치의 드라이버를 인식하고 실행할 수 있다면
컴퓨터 내부와 정보를 주고받을 수 있다.
반대로 컴퓨터(운영체제)가 장치 드라이버를 인식하거나 실행할 수 없다면
그 장치는 컴퓨터 내부와 정보를 주고받을 수 없다.
+) 장치 드라이버가 설치되어 있지 않다면 해당 입출력장치를 사용할 수 없다.
08 - 2 다양한 입출력 방법
세 가지 입출력 방식: 프로그램 입출력, 인터럽트 기반 입출력, DMA 입출력

프로그램 입출력
: 프로그램 속 명령어로 입출력장치를 제어하는 방법
입출력 명령어로써 장치 컨트롤러와 상호작용
EX) 메모리에 저장된 정보를 하드 디스크에 백업 ( == 하드 디스크에 새로운 정보 쓰기)
1) CPU는 하드 디스크 컨트롤러의 제어 레지스터에 쓰기 명령 내보내기

2) 하드 디스크 컨트롤러는 하드 디스크 상태 확인 → 상태 레지스터에 준비 완료 표시

3) 메모리에 저장된 정보를 하드 디스크에 백업
3-1) CPU는 상태 레지스터를 주기적으로 읽어보며 하드 디스크의 준비 여부를 확인
3-2) 하드 디스크가 준비되었다면 백업할 메모리의 정보를 데이터 레지스터에 쓰기

프로그램 입출력 방식:
CPU가 장치 컨트롤러의 레지스터 값을 읽고 씀으로써 이루어진다.
Q) CPU가 이 레지스터들 (입출력장치의 주소)을 어떻게 알까??

Q) 이런 명령어들은 어떻게 명령어로 표현되고, 어떻게 메모리에 저장될까?
프로그램 입출력 방식 : 메모리 맵 입출력 & 고립형 입출력
( CPU가 장치 컨트롤러의 레지스터 값을 읽고 씀으로써 프로그램 입출력 방식이 이루어지는데
이 레지스터들을 알기 위한 방법으로서 메모리 맵 입출력과 고립형 입출력 방식이 사용된다)
메모리 맵 입출력
메모리에 접근하기 위한 주소 공간과 입출력장치에 접근하기 위한 주소 공간을
하나의 주소 공간으로 간주하는 입출력 방식이다.

516번지: 프린터 컨트롤러 데이터 레지스터
517번지: 프린터 컨트롤러의 상태 레지스터
518번지: 하드 디스크 컨트롤러의 데이터 레지스터
519번지: 하드 디스크 컨트롤러의 상태 레지스터
‘517번지를 읽어 들여라’ == 프린터 상태 읽기
‘518 번지에 A를 써라’ == 하드 디스크에 A 쓰기
↪ 메모리 접근 명령어 == 입출력장치 접근 명령어
고립형 입출력
메모리를 위한 주소 공간과 입출력 장치를 위한 주소 공간을 분리하는 입출력 방식


(입출력 읽기/ 쓰기 선을 활성화시키는)
입출력 전용 명령어 사용

인터럽트 기반 입출력
인터럽트 : (하드웨어) 인터럽트의 개념 / 플래그 레지스터 속 인터럽트 비트 / 인터럽트 요청 신호 / 인터럽트 서비스 루틴
하드웨어 인터럽트는 장치 컨트롤러에 의해 발생

+) 폴링: 인터럽트와 반대되는 개념. 입출력 장치의 상태는 어떤지, 처리할 데이터가 있는지를 주기적으로 확인하는 방식

동시다발적인 인터럽트 :
입출력장치가 많을 때를 가정

인터럽트 발생 순서대로 처리??
플래그 레지스터 속 비트를 비활성화 한 채
인터럽트를 처리하는 경우.
현실은 전부 순차적으로 해결할 수 없음.
( CPU는 인터럽트 간에 우선순위를 고려하여
우선순위가 높은 인터럽트 순으로 여러 인터럽트 처리할 수 있음.)
동시다발적인 인터럽트 : 우선순위를 반영한 인터럽트

플래그 레지스터 속 인터럽트 비트가 활성화되어 있는 경우, 혹은 인터럽트 비트를 활성화해도 무시할 수 없는 인터럽트인NMI (Non-Maskable Interrupt)가 발생한 경우 CPU는 우선순위가 높은 인터럽트부터 처리한다.
→ NMI가 발생한 경우 플래그 레지스터 속 인터럽트 비트를 활성화한 채 인터럽트를 처리하는 경우
우선순위를 반영하여 다중 인터럽트를 처리하는 방법 중 하나
PIC (Programmable Interrupt Controller)
- 여러 장치 컨트롤러에 연결되어 / 장치 컨트롤러의 하드웨어 인터럽트의 우선순위를 판단한 뒤 /
CPU에게 지금 처리해야 하는 인터럽트가 무엇인지 판단하는 하드웨어
+) NMI 우선순위까지 판단하지는 않음
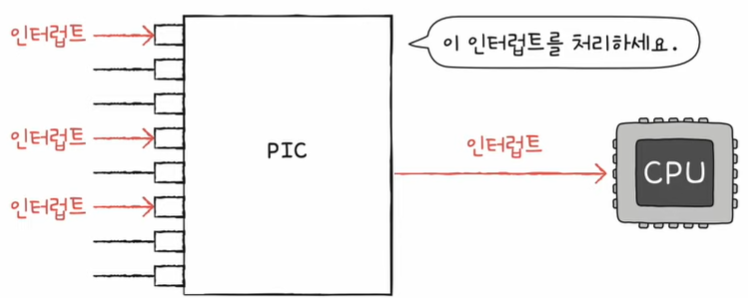
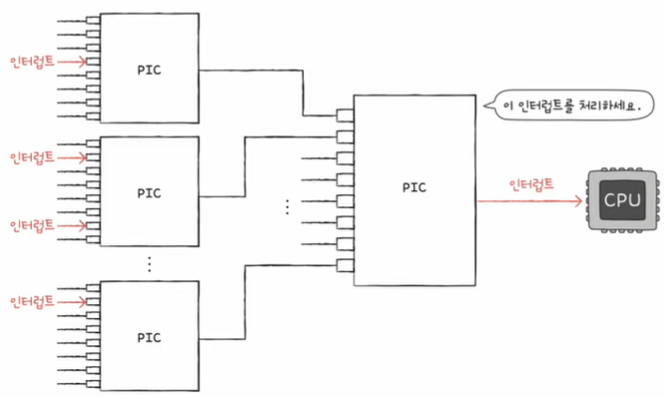
하나만 사용하지 않고
여러 개를 사용하는 경우가 많다.
DMA 입출력
Q) 프로그램 입출력, 인터럽트 기반 입출력의 공통점?
→ 입출력장치와 메모리 간의 데이터 이동은 CPU가 주도하고
이동하는 데이터도 반드시 CPU를 거친다.
입출력장치의 데이터를 메모리에 저장하는 경우↴

메모리의 데이터를 입출력에 저장하는 경우 ↴

Q) 입출력장치와 메모리 사이에 전송되는 모든 데이터가 반드시 CPU를 거쳐야 한다면
가뜩이나 바쁜 CPU는 입출력장치를 위한 연산 때문에 시간을 뺏기게 된다. 하드 디스크 백업과 같이 대용량 데이터를 옮길 때는 CPU의 부담이 커진다.
DMA (Direct Memory Access)
: CPU를 거치지 않고 입출력장치가 메모리에 직접적으로 접근하는 입출력 기능

DMA 입출력을 하기 위해서는 시스템 버스에 연결된 DMA 컨트롤러라는 하드웨어가 필요.
DMA입출력 과정
- CPU는 DMA 컨트롤러에 입출력 작업을 명령
- DMA 컨트롤러는 CPU 대신 장치 컨트롤러와 상호작용하며 입출력을 수행
( 이때 DMA 컨트롤러는 필요한 경우 메모리에 직접 접근)
- 입출력 작업이 끝나면 DMA 컨트롤러는 인터럽트를 통해 CPU작업이 끝났음을 알림


하는 동안에 CPU는
다른 작업을 수행할 수 있게 됨.


+) 앞선 예시의 DMA 과정에서 시스템 버스를 이용
BUT! 시스템 버스는 공용 자원이기에 동시 사용이 불가능함.
CPU가 시스템 버스를 사용할 때 DMA 컨트롤러는 시스템 버스를 사용할 수 없고,
DMA 컨트롤러가 시스템 버스를 사용할 때는 CPU가 시스템 버스를 사용할 수 없다.
그래서 DMA 컨트롤러는
- CPU가 시스템 버스를 이용하지 않을 때마다 조금씩 시스템 버스 이용
- CPU가 일시적으로 시스템 버스를 이용하지 않도록 허락을 구하고 시스템 버스 이용

+) CPU 입장에서는 버스에 접근하는 주기를 도둑맞는 기분이기 때문에
이러한 DMA의 시스템 버스 이용을 사이클 스틸링(cycle stealing)이라고 부른다.
입출력 버스
Q) 장치 컨트롤러가 시스템 버스에 직접 연결되어도 괜찮을까??
→ 시스템 버스를 (불필요하게) 두 번 이용하는 DMA 컨트롤러

입출력 버스를 통해 시스템 버스의 이용 빈도 낮추기

입출력 버스
e.g. PCI버스, PCI express (PCIe) 버스와 입출력 장치를 연결 짓는 슬롯

슬롯 → 입출력 버스 → 시스템 버스
+) 최근에는 메모리에 직접 접근할 뿐만 아니라 입출력 명령어를 직접 인출하고, 해석하고,
실행까지 하는 일종의 입출력 전용 CPU가 있다. → 입출력 프로세서 IOP / 입출력 채널이라 함.
기본 미션
P. 185 확인 문제 3번

(1) SRAM
(2) DRAM
(3) DRAM
(4) SRAM
P.205 확인 문제 1번

(1) 레지스터
(2) 캐시 메모리
(3) 메모리
(4) 보조기억장치
드디어.. 끝났다..
'혼공컴운' 카테고리의 다른 글
| [혼공컴운] Ch 12~13 __ 혼공학습단 11기 5주차 (1) | 2024.02.08 |
|---|---|
| [혼콩컴운] Ch 09 ~ 11 __ 혼공학습단 11기 4주차 (2) | 2024.01.31 |
| Chapter 04-2 레지스터 (2) | 2024.01.14 |
| [혼공컴운] Ch 04 ~ 05 _ 혼공학습단11기 2주차 (0) | 2024.01.14 |
| [혼공컴운] Chapter 01 ~ 03 _ 혼공학습1주차 (0) | 2024.01.07 |



